Voice AI Reliability Is a Release Gate, Not a Demo Score

Reliability is no longer the final QA checklist for autonomous voice agents. PR Newswire reported on June 24, 2026 that Coval raised a $28M Series A to define safety and reliability for autonomous voice agents—a useful signal that the market is moving from ‘better demos’ toward ‘safe enough to release.’
The enterprise question is no longer, ‘Did the demo sound good?’ It is, ‘Did this version pass a repeatable release gate?’
A Demo Score Does Not Explain Production Risk
Voice AI demos usually happen in short, controlled scenarios. Production calls are different: background noise, interruptions, incorrect CRM fields, emotional customers, disclosure language, escalation rules, and telephony latency can all appear in the same conversation. A natural-sounding demo does not prove the agent handles those combinations safely.
The failure mode is also more visible than in a text chatbot. Silence, delay, overpromising, or a missing disclosure happens in real time while the customer is listening. That makes reliability a release decision, not an afterthought after model selection.
The Market Signal: Reliability Is Becoming Infrastructure
Coval’s June 2026 funding announcement points to a broader market shift. The bottleneck for autonomous voice agents is not only speech generation quality; it is the ability to prove safety and reliability across real operating scenarios. Contact-center coverage in the same week also framed AI agents as moving beyond pilots into buying and operating conversations.
That should not be read as a single-vendor story. It is a buying-criteria story. Enterprise teams are now asking questions such as:
- Can we reproduce failure cases before rollout?
- Are high-risk responses blocked before a live customer hears them?
- Can we explain why a call was escalated to a human?
- Is the new prompt or model safer than the previous version?
- Are disclosure, privacy, and regulated-language paths tested by scenario?
The Release Gate Needs Five Stages
A Voice AI reliability model should not be a single score. It should be a staged release gate. From BringTalk’s operating perspective, five stages matter most.
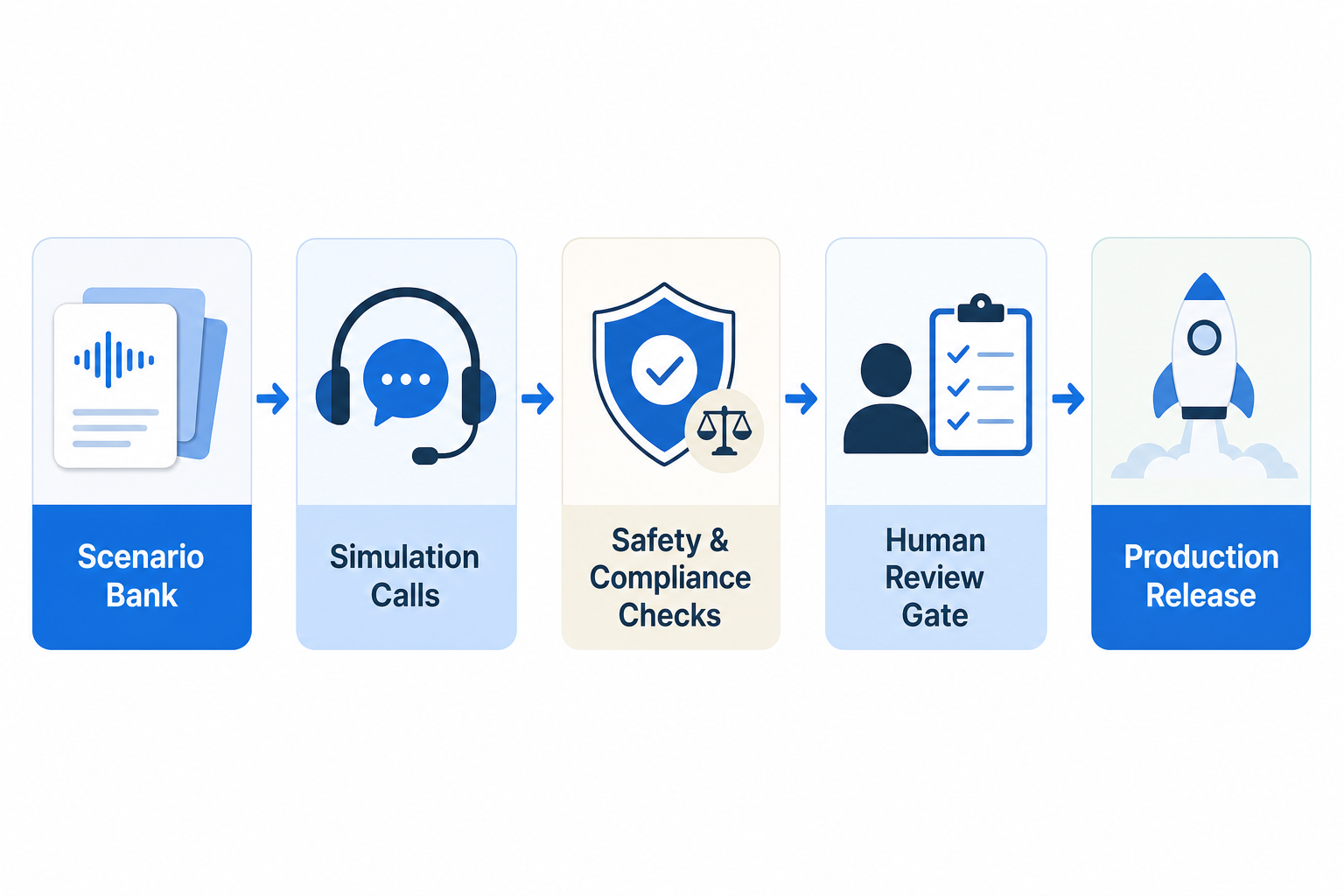
1. Scenario Bank : real intents, exceptions, and restricted responses
2. Simulation Calls : repeated call runs across STT, LLM, TTS, and telephony
3. Safety Checks : disclosure, privacy, authority, payment, refund, and promise checks
4. Human Review Gate : operating owner decides block, revise, or approve
5. Production Release : versioning, logs, rollback criteria, and rollout scope
The important part is that these stages belong to one release flow. Prompt edits, model swaps, CRM-field changes, and escalation-rule changes should all trigger the same gate again.
Measure Operating Failure, Not Just Accuracy
Voice AI reliability cannot be reduced to one accuracy number. The operating team needs to see failures that create customer harm, compliance exposure, or human-team rework.
Failure Types Worth Tracking
- Escalation failure: the agent keeps a call it should hand to a human
- Overpromising: the agent confirms refunds, approvals, bookings, or exceptions beyond authority
- Disclosure miss: recording, AI-agent, or privacy language is skipped
- Context conflict: CRM data and spoken response contradict each other
- Recovery failure: the customer corrects the agent, but the agent repeats the same mistake
These can be measured, but they should be measured against the company’s own scenarios and approval rules. Borrowed benchmarks without scope, sample size, or source are weaker than a smaller internal test set with clear decision criteria.
BringTalk POV: Reliability Becomes an Operating Asset
BringTalk treats Voice AI as an operating asset, not a one-time assistant build. The Scenario Bank is updated by sales, CS, and operations; Simulation Calls catch release risk before customers do; the Human Review Gate leaves a decision trail.
That structure matters when the same platform supports LQA, FUA, appointment booking, overdue notices, recall intake, or service routing. Each workflow can differ, but the release discipline stays shared. Over time, scenarios and failure types compound into a stronger operating system.
Bottom line: Voice AI advantage will come less from the most polished demo and more from the team that can safely release changes every week.


