Voice AI 실시간 응답의 병목은 모델이 아니라 Turn-Taking Gateway입니다

실시간 Speech-to-Speech 모델이 좋아질수록 Voice AI의 병목은 모델 호출이 아니라 순서를 누가 통제하느냐로 이동합니다. 고객이 말을 끊고, 상담 목적이 바뀌고, CRM 인계가 필요한 순간을 한 곳에서 판정하지 못하면 빠른 모델도 운영 품질을 보장하지 못합니다.
이번 주 신호: 실시간 음성 스택이 더 가까워졌습니다
Twilio는 2026년 6월 29일 Media Streams와 NVIDIA PersonaPlex를 활용한 실시간 Speech-to-Speech 튜토리얼을 공개했습니다. 같은 주 AWS는 Agent discovery, routing, access control을 위한 serverless A2A gateway와 Bedrock Model Profiler, AgentCore Memory metadata filtering 글을 연달아 냈습니다.
이 흐름의 공통점은 명확합니다. 음성 AI가 단일 모델 데모에서 벗어나 미디어 스트림, 에이전트 라우팅, 모델 선택, 메모리 필터, 접근 제어가 결합된 운영 시스템으로 이동하고 있습니다.
실시간 음성 품질은 “어떤 모델을 쓰는가”보다 “통화 중 매 순간 어떤 제어 게이트를 통과시키는가”에 더 크게 좌우됩니다.
Turn-taking은 UI가 아니라 운영 제어입니다
사람의 통화는 순서 교대입니다. 고객이 아직 말하는 중인지, 말을 끊어도 되는지, TTS를 멈추고 다시 들어야 하는지, 상담사를 불러야 하는지의 판단이 매 초 발생합니다.
Voice AI 운영에서는 이 판단을 모델 프롬프트 안에 숨기면 안 됩니다. 별도 Turn-Taking Gateway가 다음 신호를 구조화해야 합니다.
- VAD / barge-in: 고객 발화 시작·중단·끼어들기 감지
- STT partial: 최종 transcript 전의 의도 변화 감지
- Policy router: 결제, 민원, 개인정보, 이탈 위험 등 경로 판정
- Model fallback: 품질·지연·비용 기준으로 모델 교체
- CRM / handoff event: 상담사 인계와 사후 조치의 증거 기록
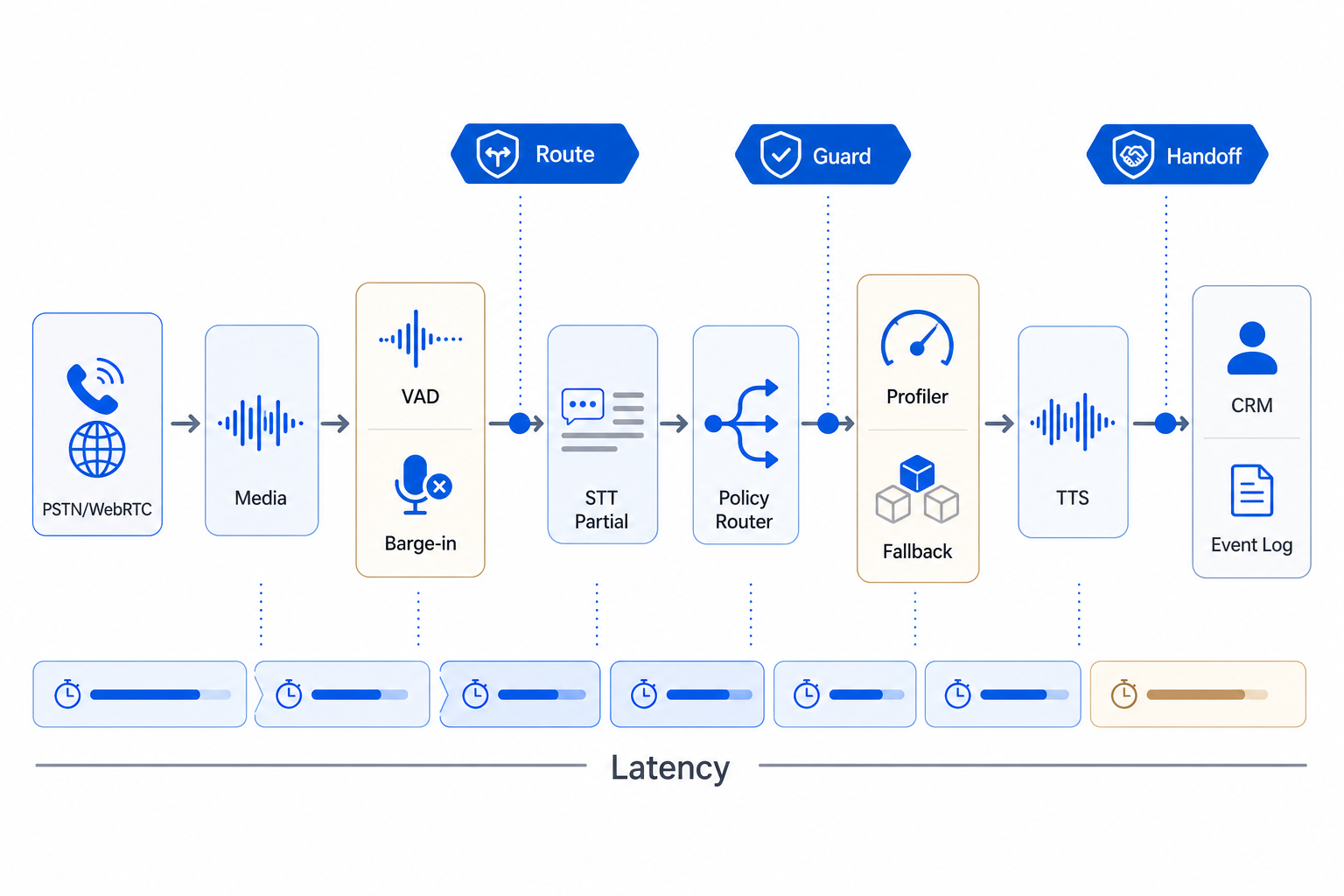
권장 아키텍처: Route, Guard, Handoff 3개 게이트
실시간 음성 스택을 운영에 넣을 때 게이트웨이는 최소 3개 결정을 분리해야 합니다.
Caller audio
→ Media stream
→ VAD / barge-in detector
→ STT partial transcript
→ Route gate: purpose, segment, next best action
→ Guard gate: PII, policy, prompt-injection, unsafe request
→ Model / tool / TTS execution
→ Handoff gate: human transfer, CRM note, follow-up task
Route gate는 고객의 목적을 정합니다. Guard gate는 말해도 되는 것과 저장해도 되는 것을 제한합니다. Handoff gate는 자동화가 멈춰야 하는 지점과 사람에게 넘겨야 하는 증거를 남깁니다.
이 3개를 한 프롬프트로 합치면 디버깅이 어려워집니다. 반대로 게이트를 나누면 실패가 어느 층에서 발생했는지 추적할 수 있습니다.
모델 선택은 런타임 정책이어야 합니다
AWS가 2026년 7월 1일 공개한 Bedrock Model Profiler 글은 모델 선택을 사전 감각이 아니라 측정 가능한 비교 작업으로 다룹니다. Voice AI에서는 이 원칙이 더 중요합니다. 같은 LLM이라도 통화에서는 지연, 안정성, partial 입력 처리, tool-call 실패 복구가 다르게 나타납니다.
운영팀은 모델을 하나로 고정하기보다 다음 정책을 두는 편이 안전합니다.
- 짧은 FAQ·예약 변경은 저지연 경로로 보냅니다.
- 민원·환불·규제성 발화는 guard가 강한 경로로 보냅니다.
- 불확실성이 높거나 고객 감정 신호가 강하면 fallback 또는 human handoff를 먼저 검토합니다.
- 모델별 응답 시간, 중단률, 재질문률, 상담사 인계 사유를 함께 봅니다.
여기서 중요한 점은 “가장 똑똑한 모델”이 아니라 “현재 통화 상태에 맞는 경로”입니다.
Memory는 많이 저장하는 기능이 아닙니다
AWS AgentCore Memory의 metadata filtering 글도 Voice AI에 중요한 힌트를 줍니다. 고객 맥락을 많이 넣는 것보다, 현재 통화 목적에 맞는 맥락만 선택하는 것이 더 안전합니다.
BringTalk 관점에서는 Customer Memory를 다음처럼 제한적으로 다루는 것이 맞습니다.
- 예약 변경 통화에는 최근 예약·지점·선호 시간만 사용합니다.
- 결제·민원 통화에는 인증 상태와 처리 권한을 먼저 확인합니다.
- Zero Retention이 필요한 구간에서는 외부 LLM에 저장 가능한 정보와 금지 정보를 분리합니다.
- 상담사 인계 시에는 “모델이 추론한 감정”보다 고객이 실제 말한 요청과 확인된 필드를 남깁니다.
BringTalk 적용: 데모보다 운영 로그가 먼저입니다
실시간 Speech-to-Speech 데모는 인상적입니다. 하지만 엔터프라이즈 운영에서는 통화가 끝난 뒤 다음 질문에 답할 수 있어야 합니다.
- 왜 이 고객은 이 경로로 라우팅됐는가?
- 어떤 guard가 응답을 제한했는가?
- 모델 fallback은 언제 발생했는가?
- 상담사 인계 사유와 CRM 기록은 일치하는가?
- 다음 Follow-Up Automation(FUA)은 어떤 증거를 근거로 실행되는가?
이 질문에 답하지 못하면 Voice AI는 빠른 음성 데모에 머뭅니다. 반대로 Turn-Taking Gateway와 운영 로그를 먼저 설계하면 LQA, FUA, 상담사 인계, Zero Retention 정책이 같은 구조 안에서 움직입니다.
운영 체크리스트
실시간 Voice AI를 검토하는 팀이라면 모델 벤치마크 전에 아래 5가지를 먼저 확인해야 합니다.
- 통화 중 barge-in 발생 시 TTS가 멈추고 STT partial이 우선되는가?
- Route, Guard, Handoff 결정이 각각 로그로 남는가?
- 모델 fallback 기준이 latency만이 아니라 정책·불확실성·고객 상태를 포함하는가?
- CRM에 저장되는 필드와 외부 LLM에 전달되는 필드가 분리되는가?
- 상담사가 이어받을 때 고객에게 같은 질문을 반복하지 않을 만큼 근거가 정리되는가?
결론: 실시간 Speech-to-Speech 모델은 시작점입니다. 운영 품질은 Turn-Taking Gateway가 Route, Guard, Handoff를 얼마나 명확히 나누는지에서 결정됩니다.
Sources: Twilio Blog (2026-06-29), AWS Machine Learning Blog (2026-07-01) — A2A Gateway, Model Profiler, AgentCore Memory metadata filtering.


