Voice AI 신뢰성, 이제 데모 점수가 아니라 릴리즈 게이트입니다

자율 음성 에이전트 시장에서 신뢰성은 더 이상 QA 마지막 체크리스트가 아닙니다. PR Newswire가 2026년 6월 24일 보도한 Coval의 $28M Series A처럼, 투자와 제품 담론은 ‘더 자연스러운 데모’에서 ‘배포해도 되는 운영 신뢰성’으로 이동하고 있습니다.
이제 기업이 물어야 할 질문은 ‘데모에서 잘 말했는가’가 아니라 ‘반복 가능한 릴리즈 게이트를 통과했는가’입니다.
데모 점수는 프로덕션 리스크를 설명하지 못합니다
Voice AI 데모는 보통 짧고 통제된 시나리오에서 평가됩니다. 그러나 실제 콜센터에서는 잡음, 끼어들기, 잘못된 고객 정보, 감정적 표현, 규제 문구, 상담사 인계 조건이 동시에 발생합니다. 데모에서 자연스러웠다는 사실은 이런 조합을 안전하게 처리한다는 증거가 아닙니다.
특히 자율 음성 에이전트는 텍스트 챗봇보다 실패의 체감 비용이 큽니다. 침묵, 지연, 잘못된 약속, 부적절한 고지는 통화 중 즉시 고객 경험으로 드러납니다. 그래서 신뢰성은 모델 선택 이후의 부속 단계가 아니라 릴리즈 판단의 중심이어야 합니다.
최근 시장 신호: 안전성과 신뢰성이 투자 항목이 됐습니다
Coval의 2026년 6월 $28M Series A 보도는 한 가지 메시지를 줍니다. 자율 음성 에이전트의 병목은 ‘말을 생성하는 능력’만이 아니라, 실제 업무에서 안전성과 신뢰성을 증명하는 체계입니다. 같은 주 컨택센터 업계 보도에서도 AI agent가 파일럿을 넘어 구매·운영 의제로 올라왔다는 흐름이 반복됐습니다.
이 신호를 단순한 벤더 뉴스로만 읽으면 놓치는 지점이 있습니다. 기업 구매자는 이제 음성 품질, latency, STT/TTS 정확도뿐 아니라 다음 질문을 함께 봅니다.
- 실패 케이스를 배포 전에 재현할 수 있는가
- 고위험 발화가 실제 통화 전에 차단되는가
- 상담사 인계 기준이 로그로 설명되는가
- 변경된 프롬프트와 모델이 이전 버전보다 안전한가
- 규제·고지·개인정보 처리 문구가 시나리오별로 검증되는가
릴리즈 게이트는 5단계로 설계해야 합니다
Voice AI 신뢰성 운영 모델은 단일 평가 점수가 아니라 단계별 게이트입니다. BringTalk 관점에서는 최소한 아래 5단계를 분리해야 합니다.
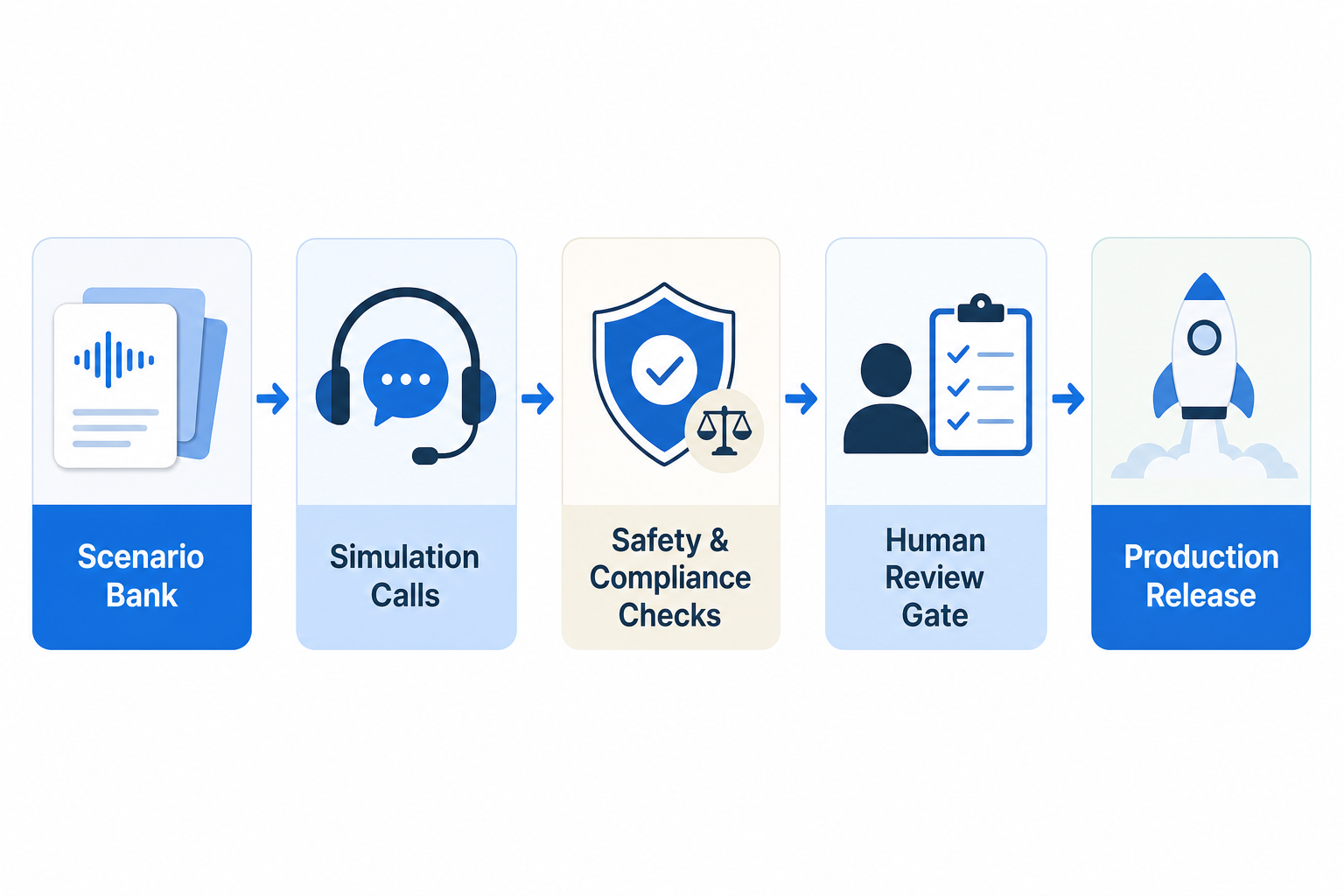
1. Scenario Bank : 실제 고객 의도, 예외 상황, 금칙 발화 수집
2. Simulation Calls : STT·LLM·TTS·telephony를 포함한 반복 통화 재생
3. Safety Checks : 고지, 개인정보, 약속/환불/결제 등 위험 발화 검사
4. Human Review Gate : 운영 책임자가 차단/수정/승인 판단
5. Production Release : 버전, 로그, 롤백 기준과 함께 배포
핵심은 각 단계를 독립된 문서가 아니라 같은 릴리즈 흐름으로 묶는 것입니다. 프롬프트 수정, 모델 교체, CRM 필드 추가, 상담사 인계 조건 변경은 모두 동일한 게이트를 다시 통과해야 합니다.
측정 대상은 ‘정답률’보다 운영 실패입니다
Voice AI의 신뢰성 지표는 단순 정확도 하나로 끝나지 않습니다. 실제 운영팀이 봐야 하는 것은 고객에게 피해를 주거나 상담사 업무를 망가뜨리는 실패입니다.
운영 실패 지표 예시
- 인계 실패: 상담사에게 넘겨야 하는 통화를 AI가 계속 붙잡는 경우
- 과잉 약속: 환불, 승인, 예약 확정처럼 권한 밖의 말을 하는 경우
- 고지 누락: 녹취, AI 응대, 개인정보 처리 안내가 빠지는 경우
- 문맥 붕괴: CRM 정보와 통화 발화가 서로 충돌하는 경우
- 회복 실패: 고객이 반복해서 정정했는데도 같은 오류를 되풀이하는 경우
이 지표들은 숫자로 관리할 수 있지만, 출처 없는 업계 평균을 가져다 붙이는 방식은 위험합니다. 기업은 자사 업무 시나리오, 실제 고객 의도, 내부 승인 기준으로 기준선을 만들어야 합니다.
BringTalk 적용: 신뢰성은 운영 자산입니다
BringTalk이 보는 Voice AI 운영의 핵심은 ‘한 번 만든 assistant’가 아니라 계속 개선되는 운영 자산입니다. Scenario Bank는 영업·CS·운영팀이 함께 업데이트하고, Simulation Calls는 배포 전 변경 위험을 확인하며, Human Review Gate는 책임 소재를 남깁니다.
이 구조가 있어야 LQA, FUA, 예약, 미납 안내, 리콜 접수처럼 서로 다른 업무가 같은 품질 체계 안에서 운영됩니다. 프로젝트마다 새로 감으로 평가하는 대신, 시나리오와 실패 유형이 누적되기 때문입니다.
결론: Voice AI의 경쟁력은 더 그럴듯한 데모가 아니라, 변경할 때마다 안전하게 배포할 수 있는 릴리즈 게이트에서 결정됩니다.


