The Real-Time Voice AI Bottleneck Is the Turn-Taking Gateway, Not the Model

As real-time speech-to-speech models improve, the Voice AI bottleneck moves from the model call to who controls the order of the conversation. If a system cannot decide when a caller interrupts, when the intent changes, or when a human handoff needs CRM evidence, a faster model will not guarantee production quality.
This Week's Signal: Real-Time Voice Stacks Are Getting Closer
On June 29, 2026, Twilio published a tutorial for real-time speech-to-speech using Media Streams and NVIDIA PersonaPlex. In the same week, AWS published articles on a serverless A2A gateway for agent discovery, routing and access control, Bedrock Model Profiler, and AgentCore Memory metadata filtering.
The common pattern is clear. Voice AI is moving from a single-model demo into an operating system that combines media streams, agent routing, model selection, memory filtering and access control.
Real-time voice quality depends less on “which model” and more on “which control gate decides each moment of the call.”
Turn-Taking Is Operational Control, Not UI Polish
Human calls are turn-taking systems. Every second, the system must decide whether the customer is still speaking, whether TTS should stop, whether the next response is safe, and whether a human advisor should take over.
In production Voice AI, those decisions should not be buried inside one prompt. A separate Turn-Taking Gateway should structure the following signals.
- VAD / barge-in: caller speech start, stop and interruption detection
- STT partials: intent drift before the final transcript arrives
- Policy router: payment, complaint, PII, churn risk and escalation paths
- Model fallback: switching models based on quality, latency and policy constraints
- CRM / handoff event: evidence for human transfer and follow-up actions
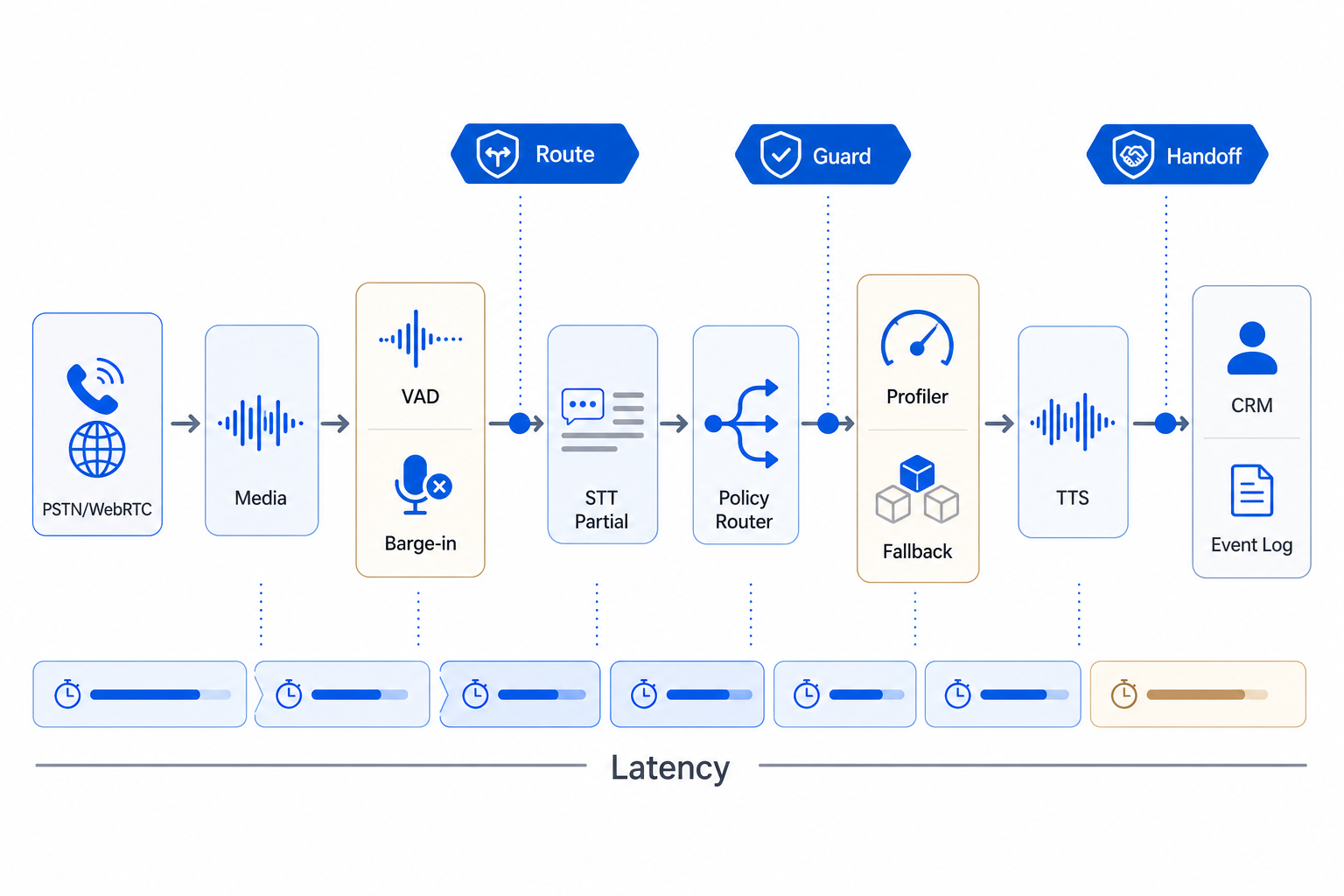
Recommended Architecture: Route, Guard and Handoff Gates
A production real-time voice stack should separate at least three decisions inside the gateway.
Caller audio
→ Media stream
→ VAD / barge-in detector
→ STT partial transcript
→ Route gate: purpose, segment, next best action
→ Guard gate: PII, policy, prompt-injection, unsafe request
→ Model / tool / TTS execution
→ Handoff gate: human transfer, CRM note, follow-up task
The Route gate decides what the caller is trying to do. The Guard gate limits what the agent may say, store or send to an external model. The Handoff gate decides when automation should stop and what evidence a human needs.
When these gates are collapsed into one prompt, debugging becomes guesswork. When they are separated, the team can identify which layer failed.
Model Selection Should Be a Runtime Policy
AWS’s July 1, 2026 Bedrock Model Profiler post treats model choice as a measurable comparison rather than intuition. That principle matters even more in Voice AI. The same LLM can behave differently under live speech conditions because partial input, tool-call recovery, latency and interruption handling all change the result.
Operations teams should avoid hard-wiring one model for every call. A safer policy looks like this.
- Short FAQ and appointment-change calls use the low-latency path.
- Complaint, refund or regulated utterances use the stronger guard path.
- High uncertainty or emotional-risk signals trigger fallback or human handoff first.
- Model response time, interruption rate, re-ask rate and handoff reason are reviewed together.
The goal is not the smartest model in isolation. The goal is the right route for the current call state.
Memory Is Not About Storing More
AWS’s AgentCore Memory metadata-filtering post also matters for Voice AI. Customer context is safer when it is filtered by purpose, not dumped into every turn.
For BringTalk-style deployments, Customer Memory should be constrained this way.
- Appointment-change calls use only recent booking, branch and preferred-time context.
- Payment and complaint calls check authentication state and authority first.
- Zero Retention segments separate fields that may be sent to external LLMs from fields that must stay out.
- Human handoff notes should prioritize verified customer requests and confirmed fields over inferred emotion.
BringTalk Application: Logs Before Demos
Real-time speech-to-speech demos are impressive. Enterprise operations require the system to answer harder questions after the call ends.
- Why was this caller routed to this path?
- Which guard restricted the response?
- When did model fallback occur?
- Does the human handoff reason match the CRM note?
- What evidence will trigger the next Follow-Up Automation (FUA)?
If the system cannot answer those questions, Voice AI remains a fast audio demo. If the Turn-Taking Gateway and operating logs are designed first, LQA, FUA, human transfer and Zero Retention policies can run inside the same structure.
Operating Checklist
Before benchmarking a real-time voice model, teams should verify these five controls.
- When barge-in occurs, does TTS stop and do STT partials take priority?
- Are Route, Guard and Handoff decisions logged separately?
- Does the fallback policy include policy, uncertainty and customer state, not only latency?
- Are CRM-stored fields separated from fields sent to external LLMs?
- Can the human advisor continue without asking the customer to repeat verified information?
Bottom line: real-time speech-to-speech models are the starting point. Production quality is decided by how clearly the Turn-Taking Gateway separates Route, Guard and Handoff.
Sources: Twilio Blog (2026-06-29), AWS Machine Learning Blog (2026-07-01) — A2A Gateway, Model Profiler, AgentCore Memory metadata filtering.


